Reddit Rate Limit (429) Explained: Fix “Too Many Requests” with a Request‑Efficient Blueprint
By Sancijun

If you searched “reddit ratelimit”, you’re probably here because something broke:
- Your script gets HTTP 429 Too Many Requests.
- You see “You’re doing that too much. Try again in X minutes.”
- Rate‑limit headers are missing, or the wait time feels unpredictable.
- The fix you found online was “sleep 10 minutes”, and that’s not a real solution.
This guide is the solution you wish Reddit’s docs were: a repeatable blueprint that keeps your client stable, respects limits, and dramatically reduces the number of requests you need in the first place.
TL;DR — The One‑Page Prescription (Keep This)
Your goal is not “avoid 429 forever”. Your goal is:
- make throttling predictable, and
- make your system request‑efficient, so throttling is rare.
Always (Control Layer)
- Use a global request scheduler (queue + concurrency limit) shared by all Reddit calls.
- Implement backoff + jitter on transient failures (especially 429).
- Use rate‑limit headers (when present) as hints—especially
X‑Ratelimit‑Resetto estimate when the window cools down. - Add a circuit breaker: when you’re clearly throttled, stop starting new requests for a while.
- Make it user‑visible: surface “queued, resuming in ~Xs” instead of failing silently.
Prefer (Efficiency Layer)
- Cache what’s safe to cache (local / edge / server) with appropriate TTLs.
- De‑duplicate aggressively (IDs, permalinks, pagination overlap, retries).
- Be selective about comment retrieval: top / high‑signal only, not exhaustive.
- Use pagination well (e.g. higher
limiton listing endpoints), but treat it as a tool—not the strategy.
Don’t (Anti‑Patterns)
- Don’t fan‑out per‑post / per‑comment requests with uncontrolled concurrency.
- Don’t “sleep everywhere” inside random functions; you’ll still stampede.
- Don’t re‑scan the same page repeatedly without caching + dedup.
Section 1 — “reddit ratelimit” is actually two different problems
Most people lose hours because they assume every rate‑limit symptom has the same cause.
Problem A: Request throttling (HTTP 429)
This is the “too many requests” category. It’s about how often your client hits Reddit endpoints.
Typical symptoms:
- HTTP 429 on GET requests.
- Sometimes you see
X‑Ratelimit‑*headers. - Waiting a short time usually recovers.
Problem B: Action throttling (“You’re doing that too much”)
This is a separate class of limits (often tied to user/account behavior) and commonly triggered by actions like posting or commenting.
Typical symptoms:
- Message includes a human‑readable wait time (“try again in 9 minutes”).
- SDKs may raise a specific exception type.
- Rate‑limit headers might not help you here.
Key takeaway: Build for both. They require different handling, but they can coexist in the same app.
Section 2 — How to read X‑Ratelimit headers (and why they might be missing)
When present, rate‑limit headers are useful signals:
X‑Ratelimit‑Used: what you’ve consumed in the current window (approximate).X‑Ratelimit‑Remaining: what Reddit thinks you have left (approximate).X‑Ratelimit‑Reset: seconds until the window resets (approximate).
But real systems must handle the messy reality:
Why headers can be missing
- You’re hitting a cached path, a CDN layer, or an endpoint variant that doesn’t include them.
- Your request is considered “unidentified” or suspicious (User‑Agent issues are common).
- You’re not using the same auth/cookie context across requests.
- You’re not actually getting a normal API response (e.g., blocked / challenged).
Practical rule
- Treat
X‑Ratelimit-*as helpful hints, not a contract. - Treat 429 as the only reliable universal signal that you must slow down.
Section 3 — The resilient client blueprint (turn 429 into “queued, not broken”)
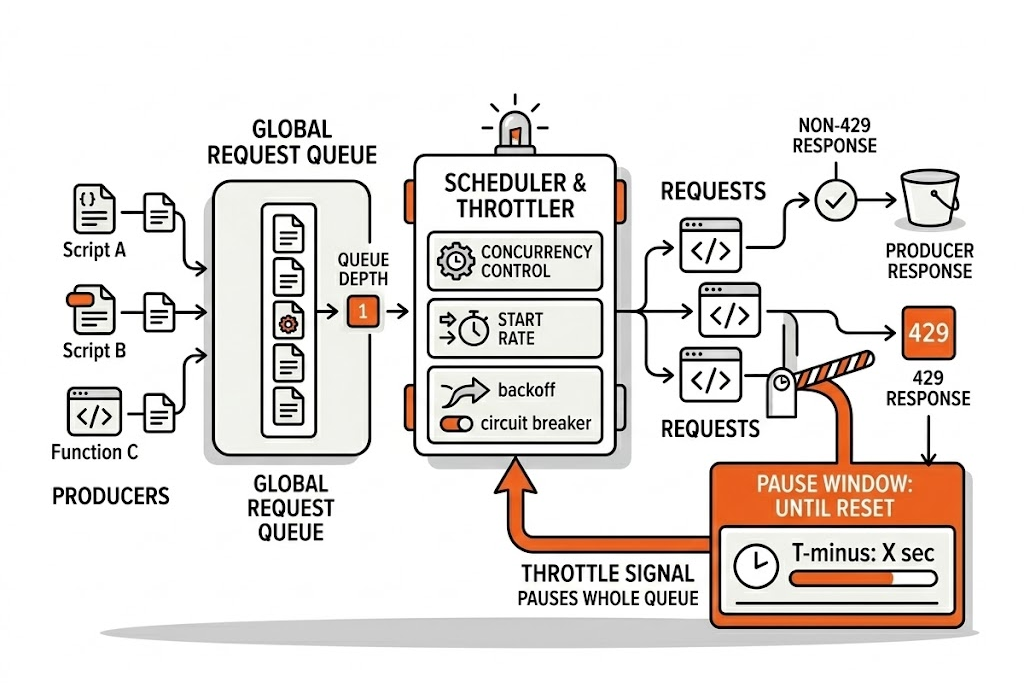
Most “fixes” fail because they’re local. You add sleep() in one place, but other parts of your app keep firing requests.
The correct approach is global:
- all Reddit requests go through a single scheduler (or one per host),
- the scheduler controls concurrency and start rate,
- throttling pauses the whole queue, not just one function.
Blueprint: a global scheduler with backoff and circuit breaker
Below is a language‑agnostic sketch you can implement in Node/Python/Go/Rust—anywhere.
state per host:
queue
active_count
next_start_time
blocked_until
enqueue(task):
push task to queue
drain()
drain():
while active_count < max_concurrency and queue not empty:
if now < max(blocked_until, next_start_time):
schedule drain() at that time
return
active_count++
next_start_time = now + min_start_interval + jitter()
run task()
on finally:
active_count--
drain()
request(url):
response = await enqueue(fetch(url))
if response.status != 429: return response
wait = parse_x_ratelimit_reset_seconds(response) or fallback_wait
blocked_until = max(blocked_until, now + wait + jitter())
retry (bounded)
What makes this “production‑grade”
- It smooths bursts (you won’t accidentally spike).
- It prevents parallel code paths from stampeding.
- It makes behavior predictable and debuggable.
- It gives you a single place to add observability and UX messaging.
Section 4 — The real pro move: request‑efficiency (reduce requests without losing quality)
Pagination tweaks alone won’t save you. You need a strategy that reduces the total number of calls required to produce a “useful result”.
Here’s the approach that works for research tools, scanners, monitors, and data collectors.
1) Cache with intent (not “cache everything”)
Cache is the difference between a hobby script and a system you can run every day.
Cache candidates:
- Listing responses (subreddit/search pages) for a short TTL.
- Post metadata and permalinks you’ve already processed.
- Comment summaries or top comments for popular threads.
Rule of thumb:
- Cache the expensive work (network calls) more aggressively than the cheap work (local parsing).
2) Deduplicate everywhere
Dedup is a force multiplier. Without it, pagination overlap and retries will quietly double your request volume.
Dedup candidates:
- Post IDs / permalinks.
- Comment IDs.
- Request signatures (URL + query params + key headers).
3) Selective comment retrieval (quality over quantity)
Comments are the fastest way to blow your quota:
- One listing page can contain 100 posts.
- If you fetch comments for each post, you’ve created a request explosion.
Instead:
- Fetch comments only for a limited subset of posts.
- Decide “which posts deserve comments” with a cheap gate: rules + heuristics, or lightweight local AI relevance scoring.
- Within a thread, prefer high‑signal comments: rank by engagement signals (e.g., score), then filter by relevance (rules or local AI), instead of crawling entire trees.
- Treat comment fetching as an “upgrade”, not the default.
4) Use pagination well (as a tool)
Use larger page sizes where available to minimize page turns.
But remember:
- Pagination helps you fetch more per call.
- It does not solve the underlying fan‑out problem.
Section 5 — Case study (high level): how Signal Hunt stays stable without brute‑forcing Reddit
Signal Hunt is an extension‑first Reddit research workflow: it analyzes the page you’re already viewing and produces an evidence‑backed report (pain, workarounds, WTP, blockers, and more).
When building on Reddit data, the hard problem isn’t “make requests faster”.
The hard problem is: stay within constraints while still producing a high‑quality research artifact.
At a high level, Signal Hunt stays stable by combining:
- Global throttling so all requests behave as one coordinated client (no stampedes).
- Request‑efficient scanning (minimize calls while preserving coverage).
- Local‑first filtering so deep fetches are reserved for the most relevant items.
- Graceful waiting UX: when throttled, the scan is queued and continues automatically, instead of failing and forcing the user to restart.
If you want to focus on the research outcome instead of building throttling, caching, dedup, and UX plumbing yourself, that’s exactly what Signal Hunt is for.
FAQ
Why am I getting 429 on the first request?
Common causes:
- Your requests look “unidentified” (User‑Agent issues).
- You’re on a shared IP that has been rate‑limited before.
- You’re making more requests than you think (retries, parallel workers, background jobs).
- You’re not consistently using the same auth/cookie context.
Fix:
- Route all calls through a global scheduler and add basic observability (count requests per minute).
- Ensure your requests identify your application responsibly.
What’s the difference between 429 and “You’re doing that too much”?
- 429 is usually request throttling at the HTTP layer.
- “You’re doing that too much” often relates to action limits and can require longer waits.
Build handling for both:
- 429 → scheduler pause window + retry policy
- action throttling → parse wait duration and delay that action pipeline
Why are X‑Ratelimit headers missing sometimes?
Because they’re not guaranteed across all delivery paths and response types. Treat them as hints, and rely on 429 + conservative scheduling.
How should I think about PRAW/AsyncPRAW ratelimit_seconds?
It’s a guardrail that tells the library how long it’s allowed to wait and retry automatically for certain rate‑limit situations. It reduces boilerplate, but you still need a plan for broader request efficiency and “unknown limits”.
Closing: make your client boring
The best Reddit integrations are boring:
- They don’t spike.
- They don’t spam endpoints.
- They degrade gracefully.
- They produce consistent results without drama.
If you’re building anything that scans Reddit at scale—research tools, monitors, dashboards—start with the blueprint above.
And if your real goal is not “handle 429”, but “turn Reddit into evidence you can build on”, use Signal Hunt to generate an evidence‑backed report in minutes.